publications
Workshop papers, preprints, and Theses
2024
-
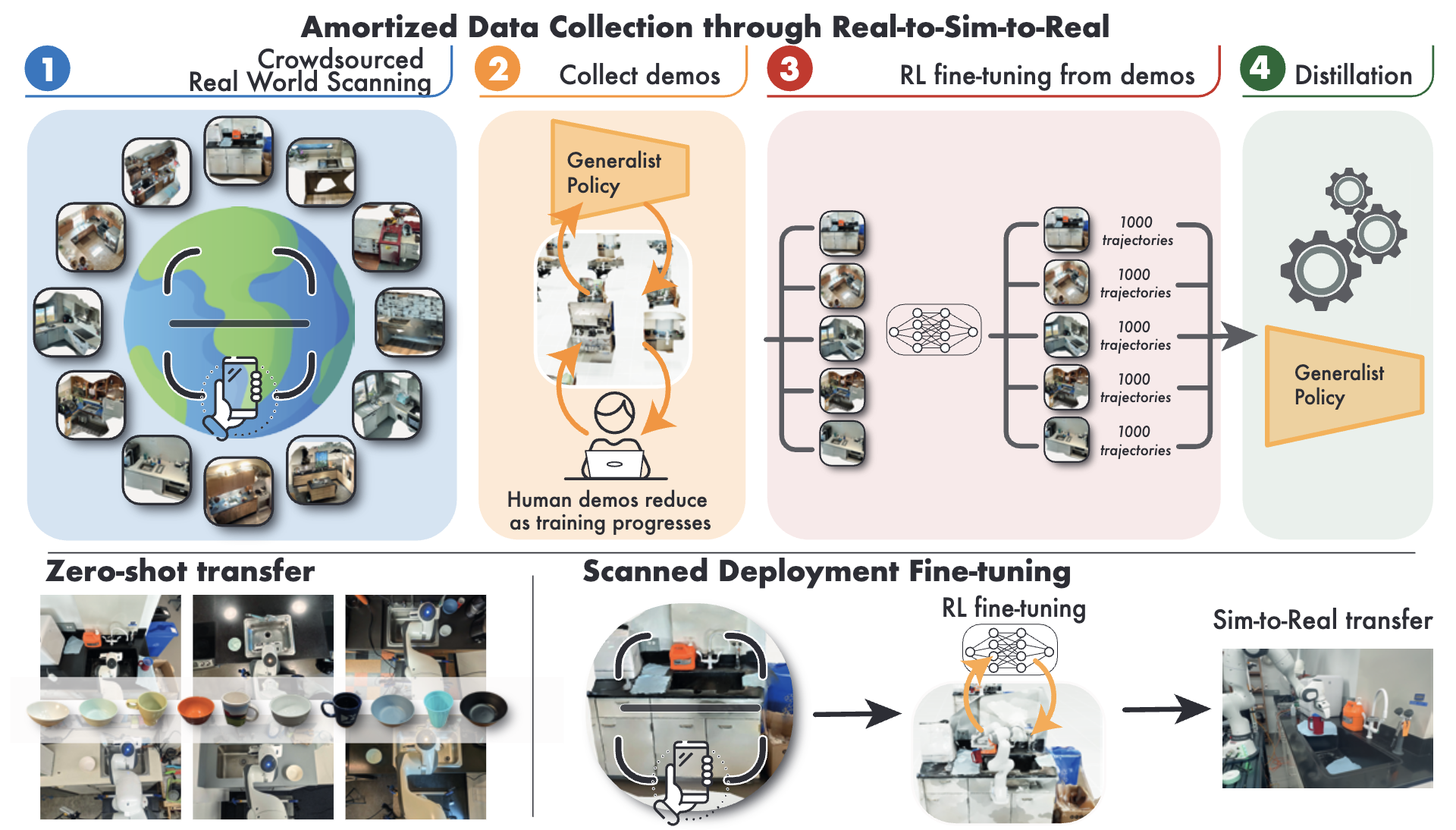 Robot Learning with Super-Linear ScalingMarcel Torne, Arhan Jain, Jiayi Yuan, and 5 more authors2024
Robot Learning with Super-Linear ScalingMarcel Torne, Arhan Jain, Jiayi Yuan, and 5 more authors2024Scaling robot learning requires data collection pipelines that scale favorably with human effort. In this work, we propose Crowdsourcing and Amortizing Human Effort for Real-to-Sim-to-Real(CASHER), a pipeline for scaling up data collection and learning in simulation where the performance scales superlinearly with human effort. The key idea is to crowdsource digital twins of real-world scenes using 3D reconstruction and collect large-scale data in simulation, rather than the real-world. Data collection in simulation is initially driven by RL, bootstrapped with human demonstrations. As the training of a generalist policy progresses across environments, its generalization capabilities can be used to replace human effort with model generated demonstrations. This results in a pipeline where behavioral data is collected in simulation with continually reducing human effort. We show that CASHER demonstrates zero-shot and few-shot scaling laws on three real-world tasks across diverse scenarios. We show that CASHER enables fine-tuning of pre-trained policies to a target scenario using a video scan without any additional human effort.
-
 DexHub and DART: Towards Internet Scale Robot Data CollectionYounghyo Park, Jagdeep Singh Bhatia, Lars Ankile, and 1 more author2024
DexHub and DART: Towards Internet Scale Robot Data CollectionYounghyo Park, Jagdeep Singh Bhatia, Lars Ankile, and 1 more author2024The quest to build a generalist robotic system is impeded by the scarcity of diverse and high-quality data. While real-world data collection effort exist, requirements for robot hardware, physical environment setups, and frequent resets significantly impede the scalability needed for modern learning frameworks. We introduce DART, a teleoperation platform designed for crowdsourcing that reimagines robotic data collection by leveraging cloud-based simulation and augmented reality (AR) to address many limitations of prior data collection efforts. Our user studies highlight that DART enables higher data collection throughput and lower physical fatigue compared to real-world teleoperation. We also demonstrate that policies trained using DART-collected datasets successfully transfer to reality and are robust to unseen visual disturbances. All data collected through DART is automatically stored in our cloud-hosted database, DexHub, which will be made publicly available upon curation, paving the path for DexHub to become an ever-growing data hub for robot learning.
-
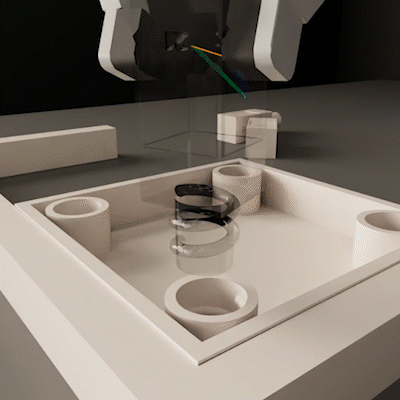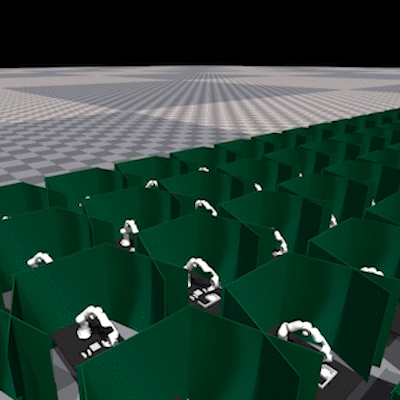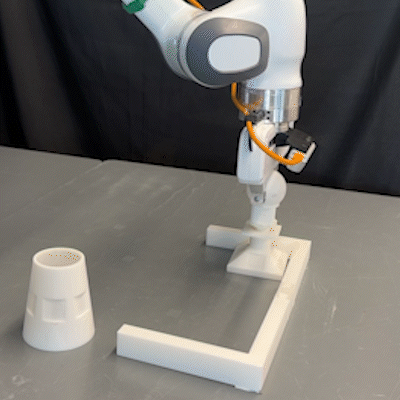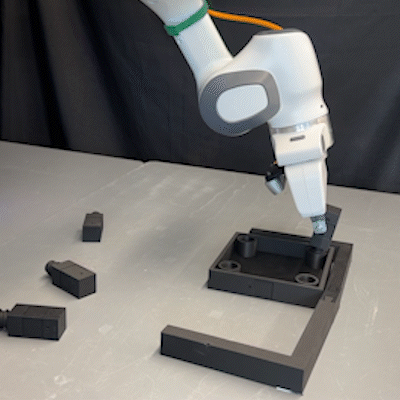 From Imitation to Refinement–Residual RL for Precise Visual AssemblyLars Ankile, Anthony Simeonov, Idan Shenfeld, and 2 more authors2024
From Imitation to Refinement–Residual RL for Precise Visual AssemblyLars Ankile, Anthony Simeonov, Idan Shenfeld, and 2 more authors2024Behavior cloning (BC) currently stands as a dominant paradigm for learning real-world visual manipulation. However, in tasks that require locally corrective behaviors like multi-part assembly, learning robust policies purely from human demonstrations remains challenging. Reinforcement learning (RL) can mitigate these limitations by allowing policies to acquire locally corrective behaviors through task reward supervision and exploration. This paper explores the use of RL fine-tuning to improve upon BC-trained policies in precise manipulation tasks. We analyze and overcome technical challenges associated with using RL to directly train policy networks that incorporate modern architectural components like diffusion models and action chunking. We propose training residual policies on top of frozen BC-trained diffusion models using standard policy gradient methods and sparse rewards, an approach we call ResiP (Residual for Precise manipulation). Our experimental results demonstrate that this residual learning framework can significantly improve success rates beyond the base BC-trained models in high-precision assembly tasks by learning corrective actions. We also show that by combining ResiP with teacher-student distillation and visual domain randomization, our method can enable learning real-world policies for robotic assembly directly from RGB images. Find videos and code at \urlhttps://residual-assembly.github.io.
-
 Diffusion Policy Policy OptimizationAllen Z Ren, Justin Lidard, Lars L Ankile, and 6 more authors2024
Diffusion Policy Policy OptimizationAllen Z Ren, Justin Lidard, Lars L Ankile, and 6 more authors2024We introduce Diffusion Policy Policy Optimization, DPPO, an algorithmic framework including best practices for fine-tuning diffusion-based policies (e.g. Diffusion Policy) in continuous control and robot learning tasks using the policy gradient (PG) method from reinforcement learning (RL). PG methods are ubiquitous in training RL policies with other policy parameterizations; nevertheless, they had been conjectured to be less efficient for diffusion-based policies. Surprisingly, we show that DPPO achieves the strongest overall performance and efficiency for fine-tuning in common benchmarks compared to other RL methods for diffusion-based policies and also compared to PG fine-tuning of other policy parameterizations. Through experimental investigation, we find that DPPO takes advantage of unique synergies between RL fine-tuning and the diffusion parameterization, leading to structured and on-manifold exploration, stable training, and strong policy robustness. We further demonstrate the strengths of DPPO in a range of realistic settings, including simulated robotic tasks with pixel observations, and via zero-shot deployment of simulation-trained policies on robot hardware in a long-horizon, multi-stage manipulation task. Website with code: diffusion-ppo.github.io
-
 JUICER: Data-Efficient Imitation Learning for Robotic AssemblyLars Ankile, Anthony Simeonov, Idan Shenfeld, and 1 more author2024
JUICER: Data-Efficient Imitation Learning for Robotic AssemblyLars Ankile, Anthony Simeonov, Idan Shenfeld, and 1 more author2024While learning from demonstrations is powerful for acquiring visuomotor policies, high-performance imitation without large demonstration datasets remains challenging for tasks requiring precise, long-horizon manipulation. This paper proposes a pipeline for improving imitation learning performance with a small human demonstration budget. We apply our approach to assembly tasks that require precisely grasping, reorienting, and inserting multiple parts over long horizons and multiple task phases. Our pipeline combines expressive policy architectures and various techniques for dataset expansion and simulation-based data augmentation. These help expand dataset support and supervise the model with locally corrective actions near bottleneck regions requiring high precision. We demonstrate our pipeline on four furniture assembly tasks in simulation, enabling a manipulator to assemble up to five parts over nearly 2500 time steps directly from RGB images, outperforming imitation and data augmentation baselines.
2023
-
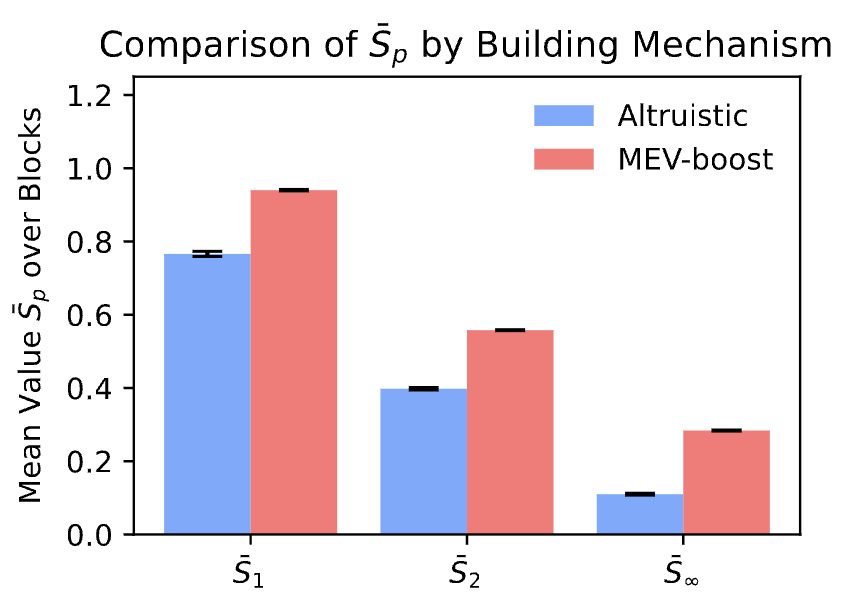 I See You! Robust Measurement of Adversarial BehaviorLars Ankile, Matheus XV Ferreira, and David ParkesIn Multi-Agent Security Workshop @ NeurIPS’23 2023
I See You! Robust Measurement of Adversarial BehaviorLars Ankile, Matheus XV Ferreira, and David ParkesIn Multi-Agent Security Workshop @ NeurIPS’23 2023We introduce the study of non-manipulable measures of manipulative behavior in multi-agent systems. We do this through a case study of decentralized finance (DeFi) and blockchain systems, which are salient as real-world, rapidly emerging multi-agent systems with financial incentives for malicious behavior, for the participation in algorithmic and AI systems, and in highlighting the need for new methods with which to measure levels of manipulative behavior. We introduce a new surveillance metric for measuring malicious behavior in this context and demonstrate its effectiveness in a natural experiment to the Uniswap DeFi ecosystem.
-
 Discovering User Types: Mapping User Traits by Task-Specific Behaviors in Reinforcement LearningLars Lien Ankile, Brian Ham, Kevin Mao, and 4 more authorsIn First Workshop on Theory of Mind in Communicating Agents @ ICML’23 2023
Discovering User Types: Mapping User Traits by Task-Specific Behaviors in Reinforcement LearningLars Lien Ankile, Brian Ham, Kevin Mao, and 4 more authorsIn First Workshop on Theory of Mind in Communicating Agents @ ICML’23 2023When assisting human users in reinforcement learning (RL), we can represent users as RL agents and study key parameters, called user traits, to inform intervention design. We study the relationship between user behaviors (policy classes) and user traits. Given an environment, we introduce an intuitive tool for studying the breakdown of "user types": broad sets of traits that result in the same behavior. We show that seemingly different real-world environments admit the same set of user types and formalize this observation as an equivalence relation defined on environments. By transferring intervention design between environments within the same equivalence class, we can help rapidly personalize interventions.
-
 Denoising Diffusion Probabilistic Models as a Defense against Adversarial AttacksLars Lien Ankile, Anna Midgley, and Sebastian Weisshaar2023
Denoising Diffusion Probabilistic Models as a Defense against Adversarial AttacksLars Lien Ankile, Anna Midgley, and Sebastian Weisshaar2023
2022
- M.Sc.Exploration of Forecasting Paradigms and a Generalized Forecasting FrameworkLars Lien Ankile, and Kjartan Krange2022
First, this paper presents a total ordering of the theoretical lower bound loss of different forecasting paradigms in the following descending order: Model selection, Model combination, Non-parametric univariate models, and Non-parametric multivariate models. Second, we create a generalized forecasting framework to test the above forecasting paradigms ex-ante. We implement the framework by creating a novel datacube consisting of daily stock prices and 100,000 quarterly reports from about 1600 global companies and several daily macro time series, all from 2000 to spring 2022. Lastly, we utilize the framework and show that modern multivariate time series approaches are powerful but domain-dependent. We demonstrate the domain-dependent accuracy by showing convincing results when predicting corporate bankruptcy risk, moderate results when predicting stock price volatility, and lacking results when finally predicting company market capitalization. Given the domain-dependent convincing results and mostly unrealized theoretical lower bound loss of multivariate approaches, we hope to encourage further research on non-parametric, multi-signal approaches that leverage a wider array of available information.
- arXivDeep Learning and Linear Programming for Automated Ensemble Forecasting and InterpretationLars Lien Ankile, and Kjartan KrangearXiv preprint arXiv:2201.00426 2022
This paper presents an ensemble forecasting method that shows strong results on the M4 Competition dataset by decreasing feature and model selection assumptions, termed DONUT (DO Not UTilize human beliefs). Our assumption reductions, primarily consisting of auto-generated features and a more diverse model pool for the ensemble, significantly outperform the statistical, feature-based ensemble method FFORMA by Montero-Manso et al. (2020). We also investigate feature extraction with a Long Short-term Memory Network (LSTM) Autoencoder and find that such features contain crucial information not captured by standard statistical feature approaches. The ensemble weighting model uses LSTM and statistical features to combine the models accurately. The analysis of feature importance and interaction shows a slight superiority for LSTM features over the statistical ones alone. Clustering analysis shows that essential LSTM features differ from most statistical features and each other. We also find that increasing the solution space of the weighting model by augmenting the ensemble with new models is something the weighting model learns to use, thus explaining part of the accuracy gains. Moreover, we present a formal ex-post-facto analysis of an optimal combination and selection for ensembles, quantifying differences through linear optimization on the M4 dataset. Our findings indicate that classical statistical time series features, such as trend and seasonality, alone do not capture all relevant information for forecasting a time series. On the contrary, our novel LSTM features contain significantly more predictive power than the statistical ones alone, but combining the two feature sets proved the best in practice.